
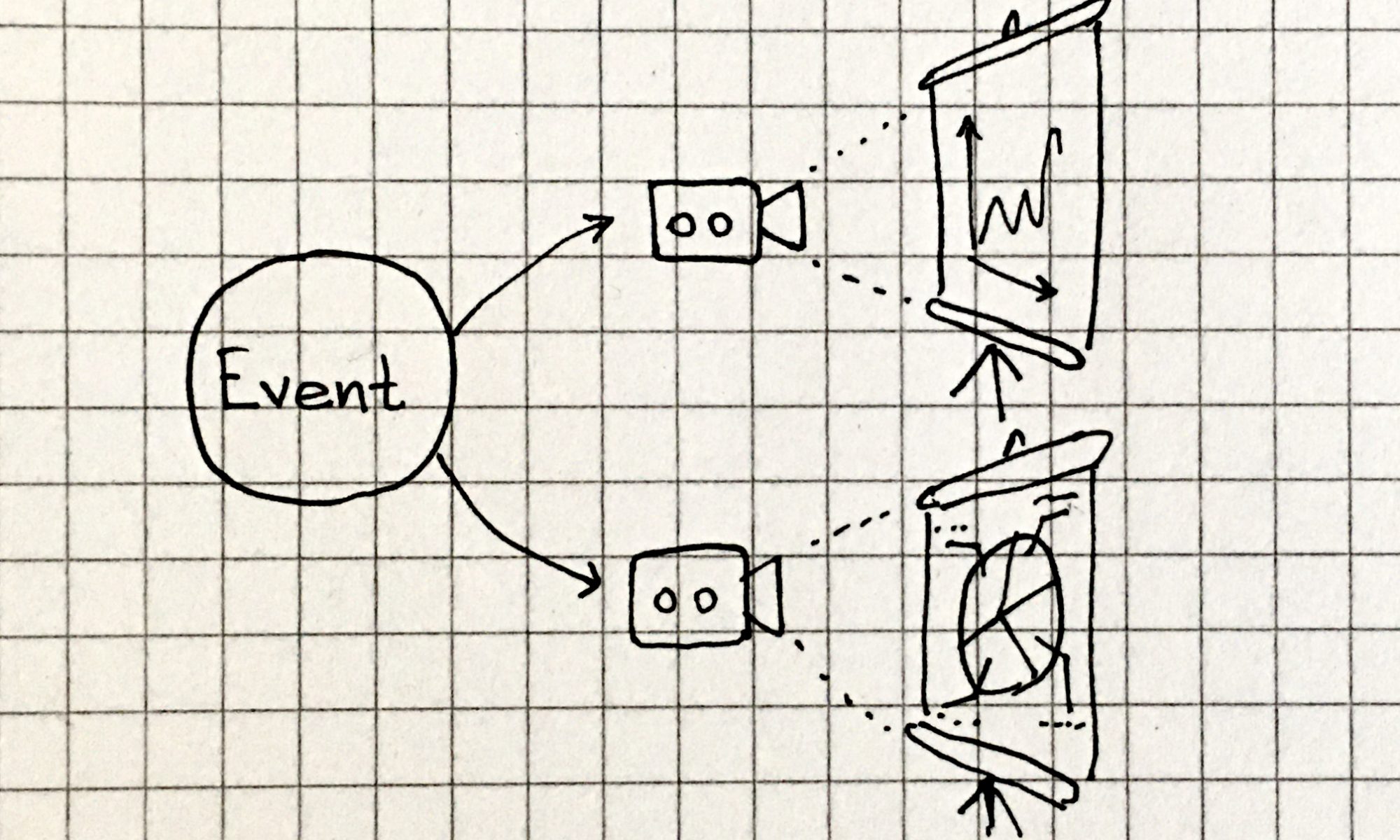
In my previous post I explained why CQRS matters and why you should adopt it if you really care your product and don’t want data growth to become a bottleneck rather than a success in your business.
Now I’m gonna dig a bit more. I want to show you how CQRS works under the hood.
Command/Query responsibilities
CQRS stands for Command Query Responsibility Segregation, and its name reveals how it works at its core.
As stated in the previous post, a software needs two data models in order to face the data growth: on model to hold the application state, and one to handle the numbers.
Well, let’s start from naming things. The requests sent to your application can be split in two main categories:
- requests that do change the application state (e.g.: creating a new user, submitting an order, performing a bank transaction, etc.). These requests are called commands.
- requests that only read your data and do not change the application state (e.g.: counting the number of registered users, getting the details of one user, getting the account balance). These requests are called queries.
CQRS aims to split your application in these two main areas: the commands and the queries. These have totally different structures, architectures and purposes.
Command vs Query
Usually when a command is sent to your application (e.g.: via an HTTP request), the business logic gets involved in order to determine whether or not the request can be satisfied. The typical steps are:
- Parse the request (return an error in case of bad syntax/arguments)
- Load the resource state from the storage
- Ensure that the requested action is allowed basing on the resource state
- Eventually apply and persist the change
As an example, imagine a banking application with a business rule stating:
A debit transaction is allowed if the requested amount is not higher than the balance
(i.e.: the account balance cannot go negative).
Some API is then designed to handle the command. The API code will look like the following:
- load the bank account from the storage (it can involve multiple tables)
- verify that the account balance covers the requested amount
- update the balance
- commit the update to the storage (hopefully with a proper concurrency management)
This is how things work, regardless of the database type.
And that just works fine with the classical one model to rule them all approach: the developer designs one database schema along with the code that handles that model.
What’s new in the CQRS architectural pattern, however, is the query model: when it’s time to query your application to get the numbers, the designated schema should be an ad-hoc set of tables. That is: the model that holds the application state is not touched by queries, it is just read and updated when a command is sent.
But how does that work? How is it possible for a microservice to handle these two different models?
Under the hood
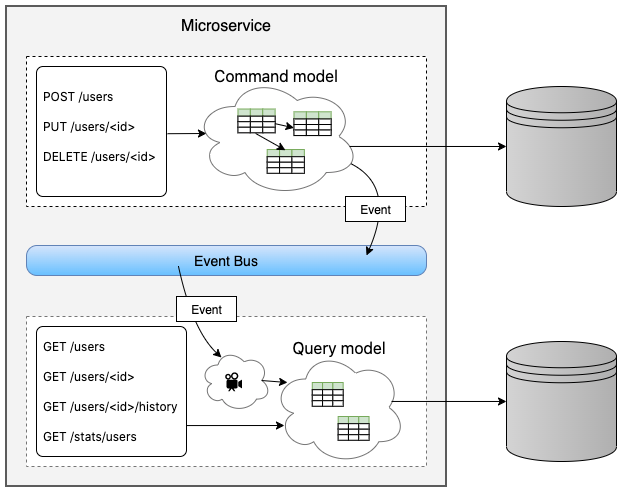
As illustrated in the above diagram, the application is logically split in two models.
The command side handles all the incoming commands: it is invoked when a POST, PUT or DELETE request is sent. The command model and the business logic are involved.
The query side handles all the incoming queries: it is invoked when a GET request is sent. The query storage is used in read-only mode.
Event Bus is the bridge between the two. Whenever a command is processed without errors and the resource updated into the storage, a domain event is emitted to notify whoever is interested in. An event bus can be implemented in a lot of different ways, but that’s not the core point. What matters is that by dispatching domain events, the microservice itself can capture that same events and use them to update the query model.
This is the core point: by introducing an event bus, the business logic is not messed up with additional code that writes the same data in different places and formats. This means that the command side just processes the commands, ensures that the business logic is not deceived, applies the changes and then returns the result. Nothing more, nothing less. Pure business logic.
In a totally asynchronous way, the domain events dispatched by the command side get captured and processed by the query side to update its model.
The two sides are processing the same requests at different times and speeds: should the query model need some time to update its model, the command execution time would not be affected at all.
This however introduces a lag between the models.
But who is in charge of handling the events in the query model?
Attach the cloners
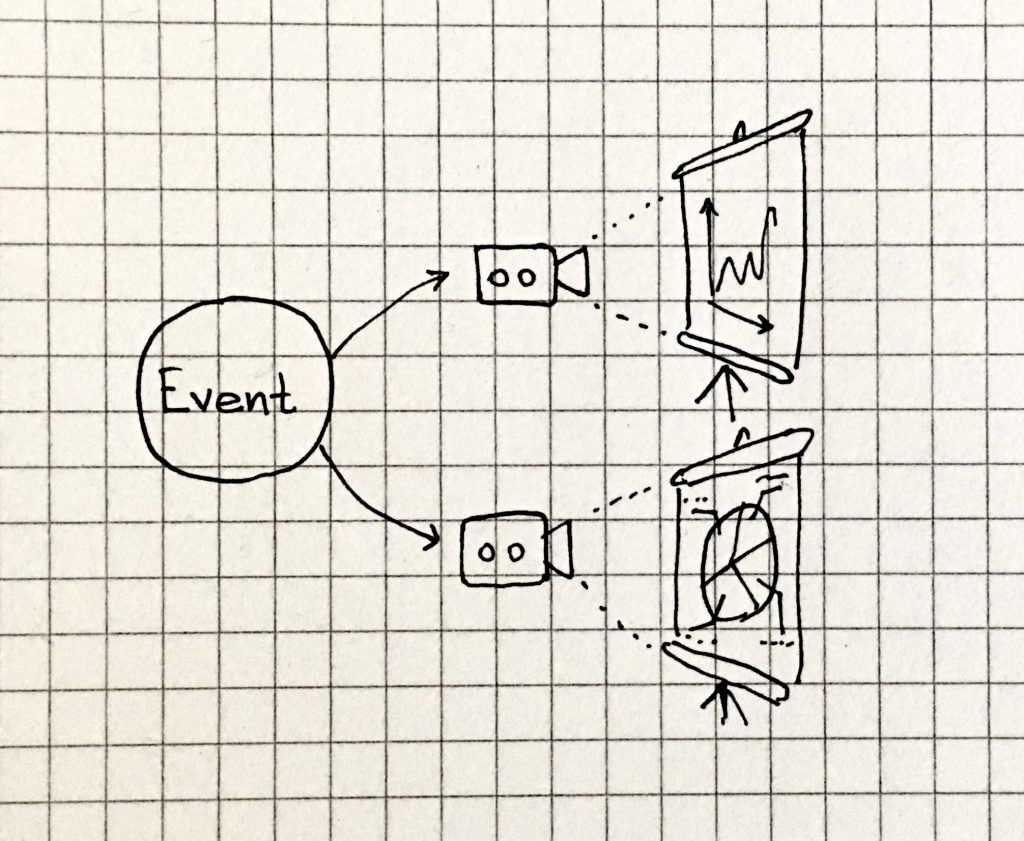
The query model is also known as projection: data coming from the command side is projected – that is represented – in very different ways, and each projection has a specific purpose, depending on the usage for which it has been thought.
Hence the key point in the query model is the projection. It is the microservice component that subscribe to specific business events and transforms their payload to some other data format. One microservice can have several projectors, handling the same events, to write the same data to totally different tables and formats.
As an example, think of a domain event for a debit transaction in a banking application.
When a debit request is sent to the microservice and the debit is successfully applied, an event is dispatched. Such event would most probably carry a payload like the following:
{
"name": "AccountDebited",
"date": "2017-12-18T17:23:48Z",
"transactionId": "tx-7w89u12376162",
"accountId": "IT32L0300203280675273924243",
"amount": {
"currency": "EUR",
"amount": 42
}
}That event can be captured by the same microservice that triggered it and routed to different projectors, who in turn update different projections. For example by:
- appending one row to the “Transactions” table, that just contains the transactions history
- updating one row in the “Balances” table, that contains one row for each account, with its current balance and the last update time
- updating one row in the “Monthly Expenses” table, that contains the sum of debit transactions for a baking account relative to one month; the table unique key is the [“account_id”, “month”] columns pair (the month can be extracted from the “date” field of the event payload, e.g.: “2017-12”)
By doing this, the application does not need to transform “the one” data model on the fly each time a query is performed by an API. Rather, it can rely on different data models to pick the requested data from, depending on what the query is asking for.
The query model already have materialized data.
What’s next?
In the next episode, CQRS Episode III – Rewind of the sync, I’ll show how to rebuild projections in case of bugs or migrations, and how the same applies when you need to build a brand new projection.
Stay tuned!

Antonio Seprano
Apr 2020, still covid-free.