A pool is generally used to create a set of resources at boot time (i.e.: when the process is starting), and it can be configured to either create all the resources at the same time, or to just create a bare minimum set of resources to be used in the average load, and to only increase them (up to some limit) at need.
This has several effects both at runtime level and at code level.
At runtime, pools will certainly improve the average performances of your application because the resources required by each handler have already been instantiated, and in the average cases it is more likely that the resource is ready to use. Also, pools prevent the process’ memory from growing indefinitely, because they limit by design the number of allocable resources, and this pushes to a design that strive to reuse the same resources as much as possible.
At code level, on the other hand, you will need to be cautious because pools are not as easy at they might seem. Nothing comes for free.
Common usage for pools
A common use is to handle database connections. Designing an application to create a new database connection to serve an incoming HTTP request has some benefits, but also some drawbacks; creating one connection per HTTP request may work on a small scale, when your application is not used too often, and the average number of HTTP requests is low, but it doesn’t scale well as your process receives a growing number of incoming requests. The more requests it must handle, the more the database connections it needs to create. But creating, holding, using and terminating database connections has an impact both on the memory usage and on CPU time. Not to mention the consequences that this design has on the database server, which must in turn be able to handle tons of incoming connections as well:
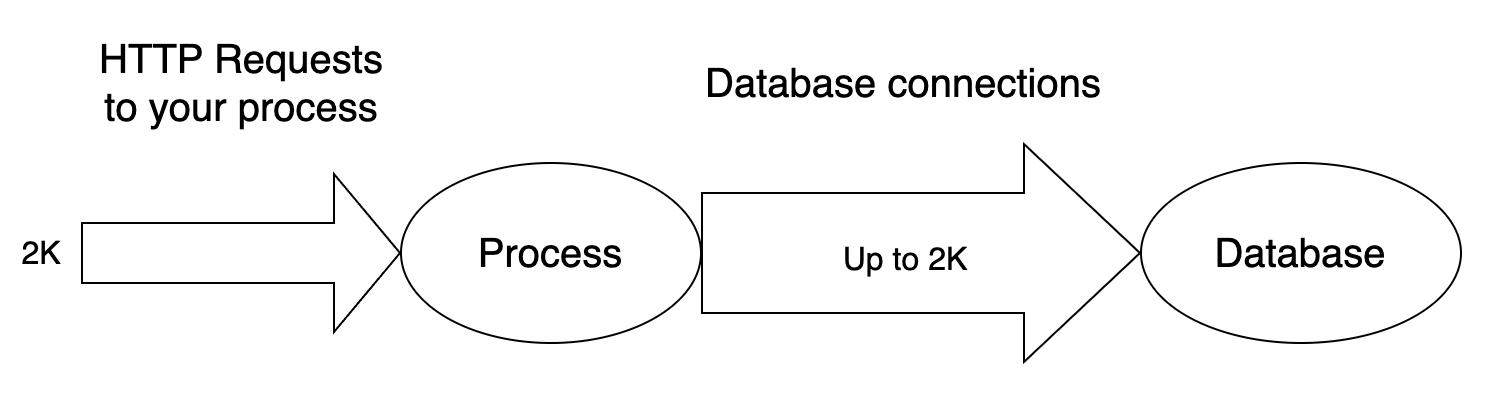
And things can only go worse for the database as your application scales, and more instances are spawn to handle the incoming HTTP traffic:
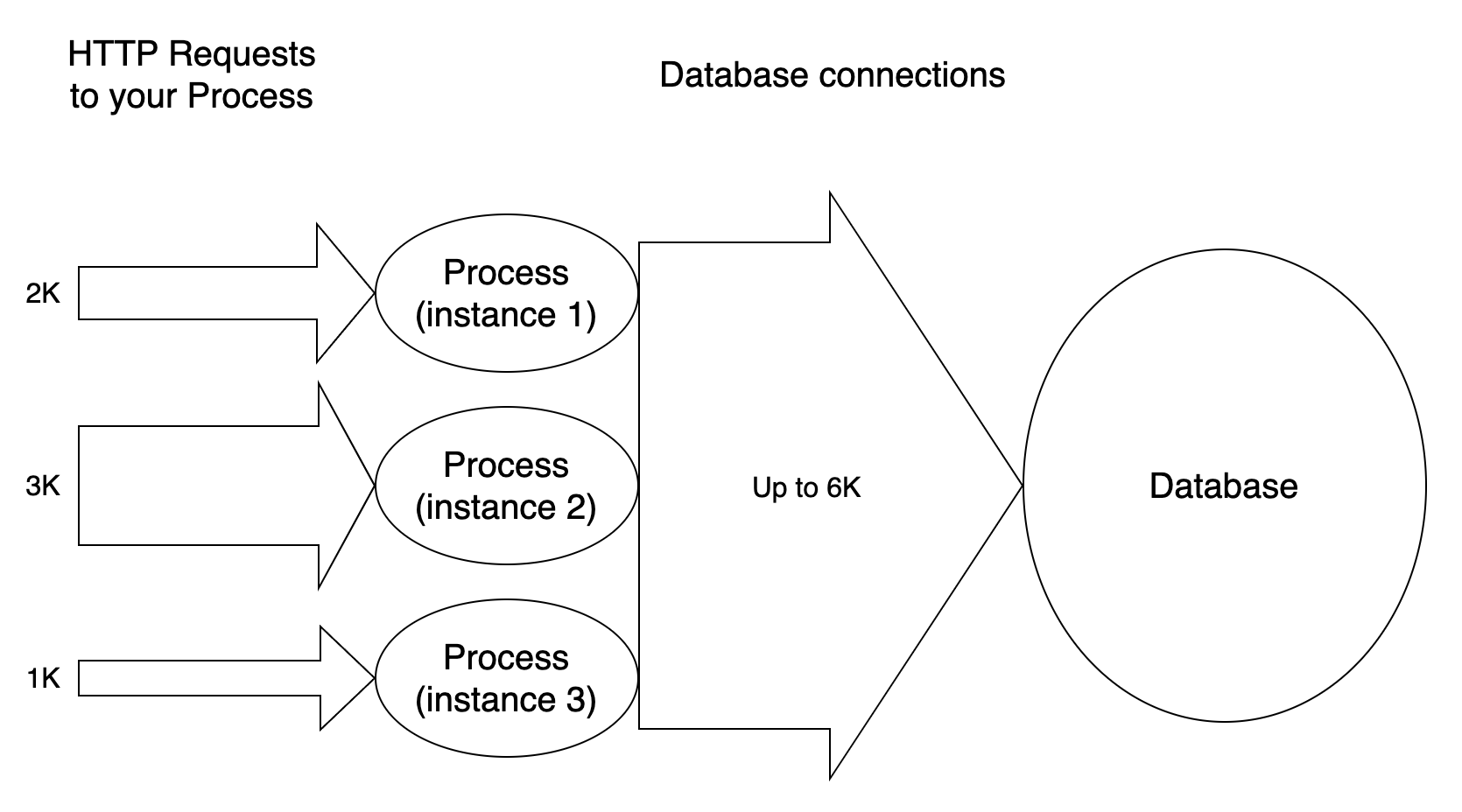
But a process that receives an incoming request doesn’t need a database connection for all the time that it is serving the request, it needs that connection only for some of the time, and this means that your process might reuse the same connection to handle two different incoming requests, assigning it to the two handlers as they need it (by means of some synchronisation mechanism, of course).
This lowers the overall number of connections to the database, and decreases the memory required by your process to handle the incoming requests as well:
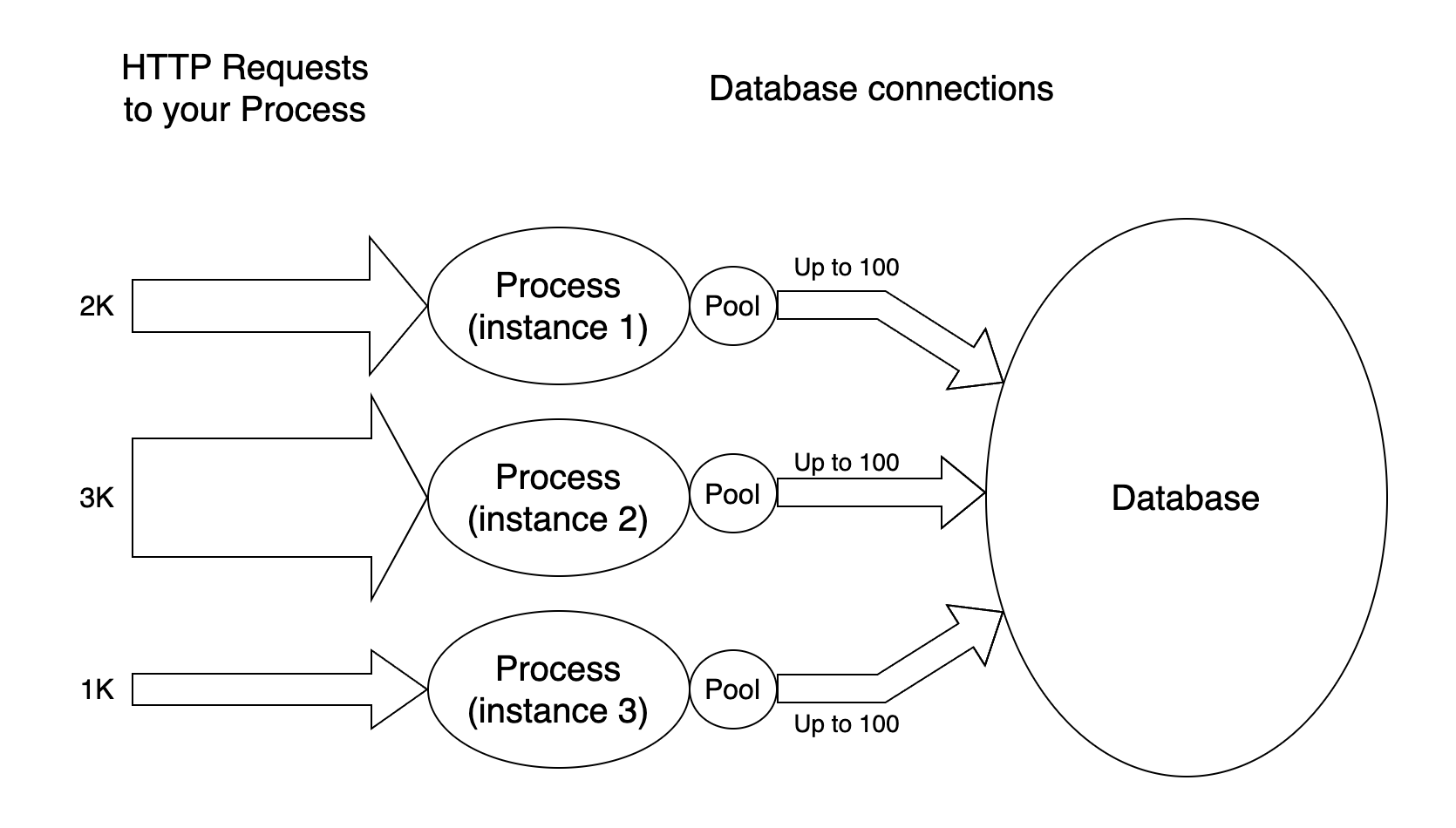
The Pool design pattern
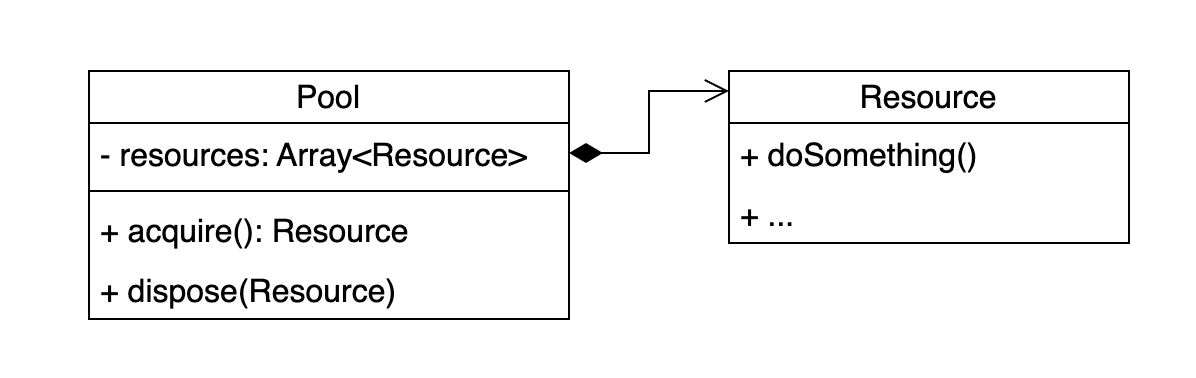
The basic Pool design pattern is pretty straightforward: it holds a collection of resources of some given type, and releases them on demand. Clients that want to use a resource must ask the pool, use the resource and then return it to the pool when it isn’t used anymore. The pool takes care of instantiating new resources and tracks which one is available and which one is not, and makes resources available again when a client returns it.
When the pool becomes empty (all the resources have been borrowed), and the pool size is at its max, no new resources are created and the client that is trying to acquire a resource is locked until a resource is returned. Nothing changes from the client’s point of view. Sooner or later a resource will be disposed, and the client waiting to acquire it will unlock and will get its resource. From its perspective, it doesn’t matter whether the request to acquire a resource lasted some milliseconds or some hundreds, it was just a call to a method that returned an object.
Despite its simplicity, however, the Pool design pattern hides some common pitfalls that you mast pay attention to. First of all: how should your code use a pool? Are the acquire/dispose methods enough? What do you get, when you acquire a resource?
How to properly use a pool
A pool, as stated before, creates resources on your behalf and holds them as long as it can. The same resources are used over and over again through the lifecycle of your process, and this means that the resources that you get can be in an invalid state. You need to design your Resource in a way that you can test it before you can use it.
In the example of the database connection, there’s certainty that the connection that you get from the pool will still be up. Clients shouldn’t trust the status of the resource returned by a pool, because it has most certainly been used by some other service.
First rule of the pool: you don’t talk to the pool
So, you design the application to give each service a new instance of the DBConnection abstraction, with a design like the following:
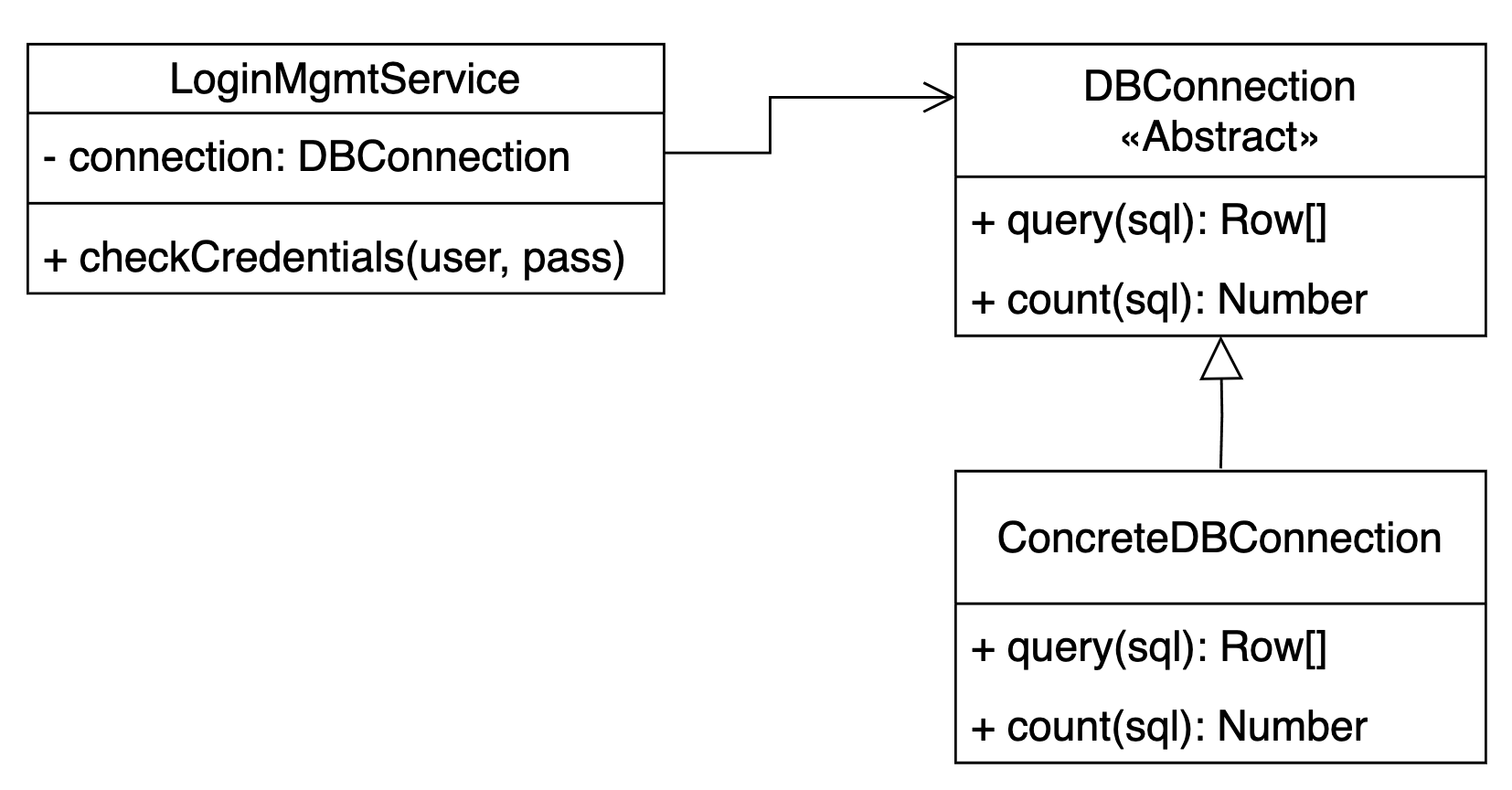
And then you write your LoginManagementService like follows:
class LoginManagementService {
constructor(
private readonly conn: DBConnection
) {}
/**
* Checks if the provided credentials belong to some user
*
* @throws UserNotFoundException
* @throws InvalidPasswordException
*/
function checkCredentials(username, password) {
const user = this.conn.query('SELECT * FROM users WHERE ...');
if (!user) {
throw new UserNotFoundException();
} else if (user.password !== password) {
throw new InvalidPasswordException();
}
}
}A common mistake is re-thinking your application’s services to use a pool, making it clear in the code that you’re using it:
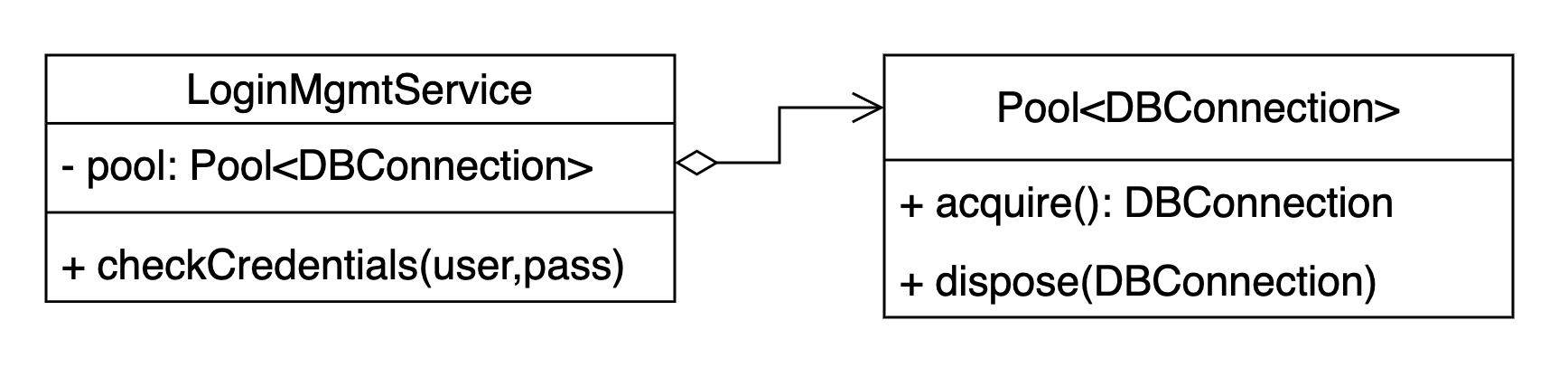
and changing your code accordingly:
class LoginManagementService {
constructor (
private readonly pool: Pool<DBConnection>
) {}
/**
* Checks if the provided credentials belong to some user.
*
* @throws UserNotFoundException
* @throws InvalidPasswordException
*/
function checkCredentials(username, password) {
const conn = this.pool.acquire();
const user = conn.query('SELECT * FROM users WHERE ...');
if (!user) {
throw new UserNotFoundException();
} else if (user.password !== password) {
throw new InvalidPasswordException();
}
this.pool.dispose(conn);
}
}This might seem a good code at a first sight: it only changes a little bit, the business logic is pretty much the same, and it acquires and releases the connection as agreed. But the devil is in the detail.
Despite the appearance, the code is error prone. When one of the exceptions is thrown, the code does not reach the point where the connection is returned to the pool, effectively leaking it for ever. That connection will never be returned to the pool, by any chance. The pool has now one connection less to share between services. As you design your code like this, there will be more and more chances to leak resources from the pool. Sooner or later, the pool will become empty and the processes that try to acquire connections will hang forever.
Designing your project to make explicit use of a pool is not a good idea, unless you’re very disciplined. And, even in that case, don’t design your application like this:
Instead, hide the pool behind some object that makes your code unaware of it. In the above example, one might create one ad-hoc implementation of the DBConnection abstraction to hide the pool and give the services the illusion of using a simple database connection:
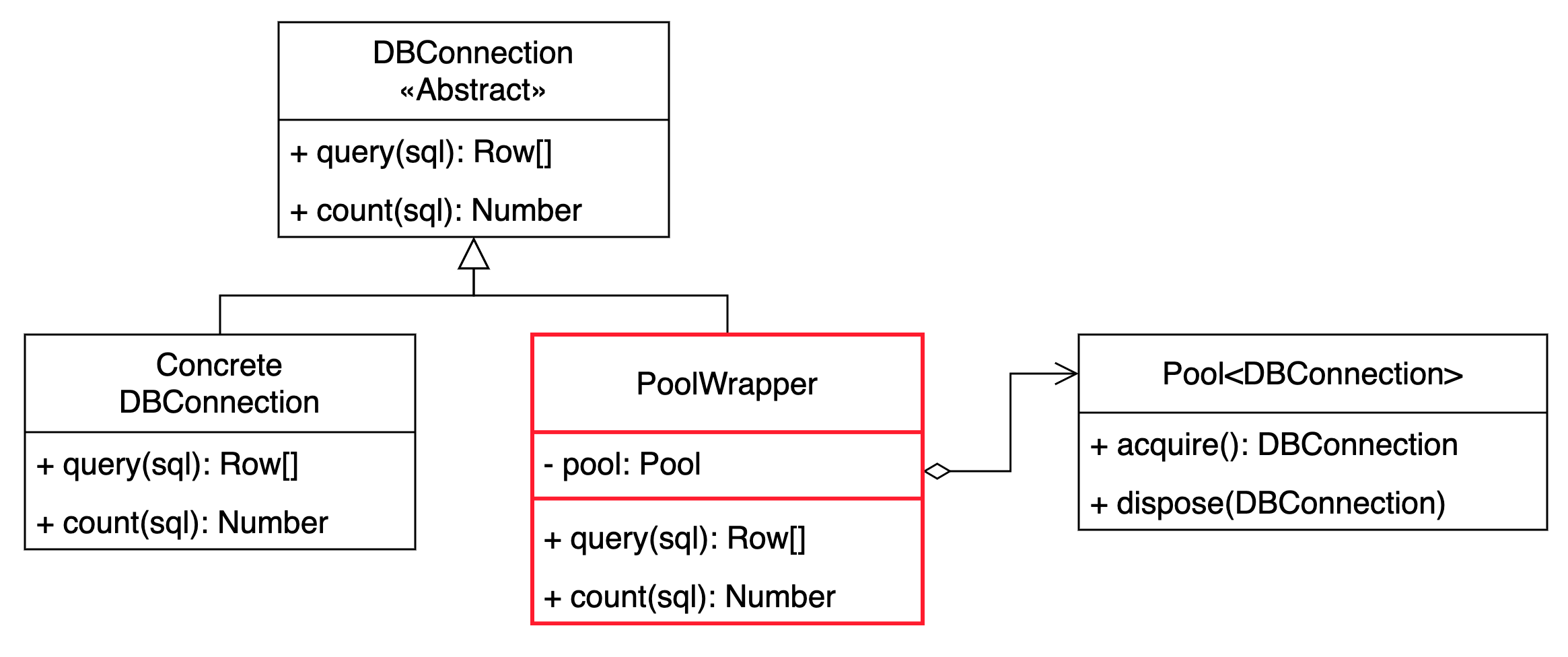
Since your service doesn’t care what implementation of the DBConnection abstraction it receives, you can write one more implementation that just takes care of interacting with the pool. Under the hoods, the PoolWrapper implements the two query() and count() base methods to acquire one real DBConnection from the pool, performing some operation with it, and returning it to the pool. Just like in the following snippet:
class PoolWrapper implements DBConnection {
constructor(private readonly pool: Pool<DBConnection>) {}
function query(sql: string): Row[] {
const conn = this.pool.acquire();
try {
return conn.query(string);
} finally {
this.pool.dispose(conn);
}
}
function count(sql: string): number {
/* pretty much the same logic */
}
}Of course, this is just an example. You should design the wrapper depending on your real case scenarios.
Anyway, hiding a pool behind some wrapper makes your code way more resilient than designing it to handle it directly, as you can rely on specific, transparent components to trustworthy handle the pool acquire/release flow behind the scenes.
Second rule of the pool: you don’t trust the pool
The second rule to follow when you introduce a pool in your project is to never trust what the pool returns to you. Once you get some resource by the pool, you must ensure that it’s still valid, and this is even more true if the pool contains long-lived connections. If it is not, just tell the pool to destroy it and then get a new one. Repeat until you get a resource that is in a valid state. Then you can safely use it.
Pools typically expose some methods to destroy a resource instead of just disposing of it. These functions will take care of removing the resource from the pool, giving the resource being destroyed one last chance to clean up resources / handlers. The pool will then use its internal policy to determine wether a new resource should be instantiated to replace the one just gone or not.
The logic to ensure that a resource is still valid can be put either in the PoolWrapper component (see previous point), or in some decorator of the pool. Anyway, it is a strongly recommended approach even for security reason.
This is the approach you should follow when using something from the pool:
- Get an item from the pool
- Ensure the item is still valid
- Use it as long as you need it
- Clean the object before putting it back into the pool
- Put the object back into the pool
This makes the design more secure, because you can trust that a best-effort approach has been used to remove any sensitive information from the items after their use.
Think of a SaaS service that must establish a pool of connections to the same database server, but customer’s data is segregated in different schemas. Every time a request arrives to the service, it must chose the right database schema depending on the request being served. You don’t want developers to write code that takes care of choosing the right database at business logic level: should the developer forget to switch to the right schema, the damage could be enormous. A pool wrapper might be designed to automatically switch the connection to the proper schema before using it to perform the query, and to switch it back to some empty/unused schema before releasing it.
You design that behaviour once and for all.
How to properly size a pool
Pool can be configured to create all the instances of Resource at once, for example if you know in advance that you won’t need less resources than that, or if you want to make a constant use of memory. But they also allow you to create a min/max configuration: the pool will start with a bare minimum set of resources, creating new instances only when needed. In this case, a pool can destroy the exceeding resources immediately after they’re returned, or after some grace period, trying its best to reuse the exceeding resources as much as possible.
It is up to you to tune your pool with a policy that best fits your needs.